엔티티 저장 시 Select 쿼리를 호출 하는 이유
⏰ 성능 이슈 발생
서비스 로직을 테스트 하는 중이었습니다.
- 클라이언트는 api 호출 시, naver map api 로 부터 조회 받은 식당 ID 값과 서버로 보내준다.
- 서버는 식당 ID 값과 추가 정보를 DB 에 저장한다.
간단한 로직이기에 문제는 없을 거라 생각했습니다. 그런데 식당 정보를 DB 에 저장할 때 select 쿼리가 호출됐습니다..
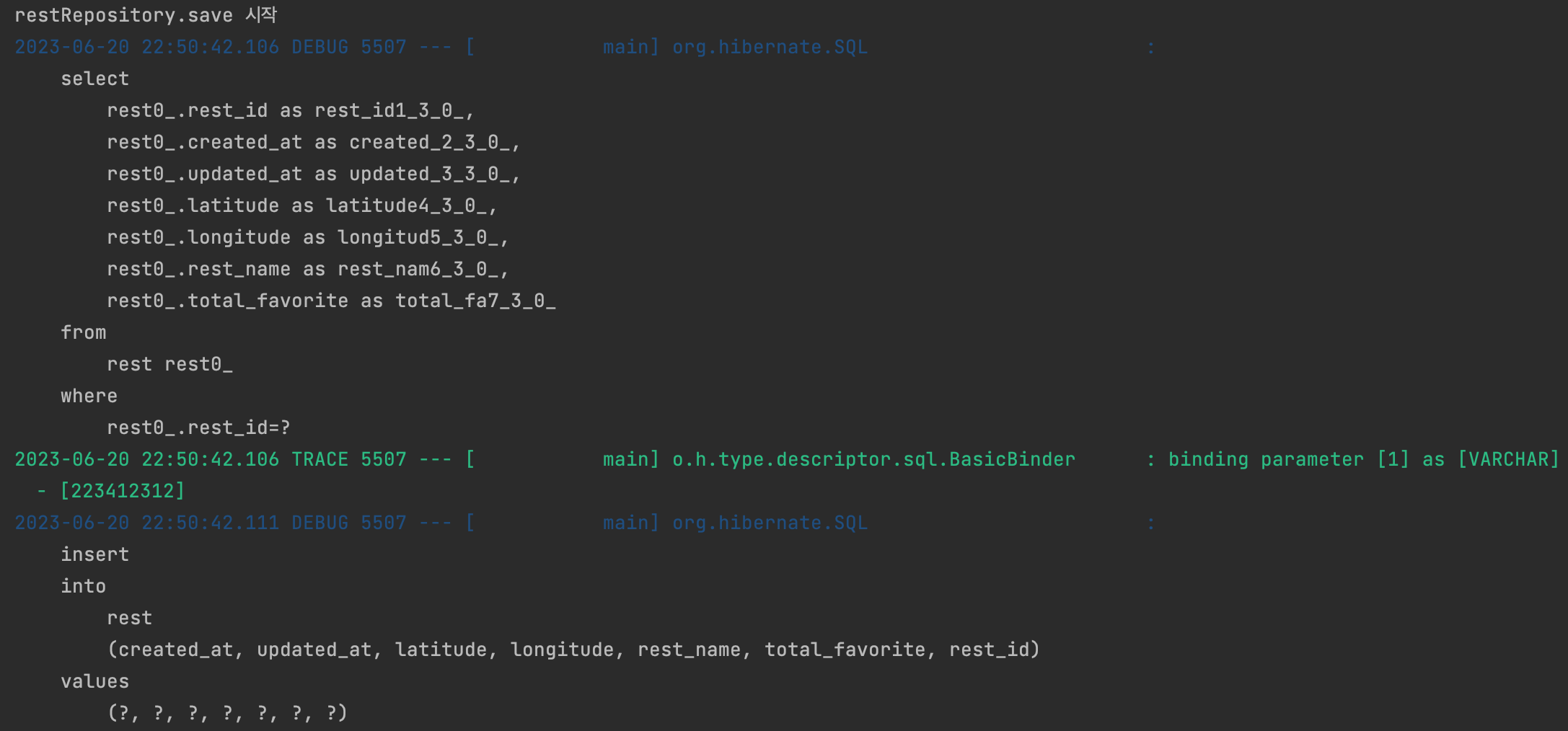
Insert 쿼리를 호출하기 전에 select 쿼리가 반복적으로 호출된다면, 클라이언트의 api 호출 수만큼 select 쿼리가 호출되는 것입니다. 서버에 불필요한 부하가 추가되는 로직이므로 수정이 필요했습니다.
🔍 성능 이슈 원인
save
엔티티를 저장하는 save 메서드는 아래 코드로 구현되어 있습니다. 저장될 엔티티가 새로운 엔티티인지 확인합니다. 새로운 엔티티면 저장하고, 아니라면 merge 메서드로 업데이트 합니다.
// SimpleJpaRepository
@Transactional
@Override
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null.");
if (entityInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
return em.merge(entity);
}
}merge
영속 컨텍스트에서 merge 의 동작방식은
- merge() 실행 2. 엔티티의 식별자 값으로 1차 캐시에서 엔티티를 조회한다. 3. 존재하지 않으면 DB에서 조회 하고, 1차 캐시에 저장한다.
- 조회한 엔티티의 값을 병합한다. (밀어 넣기, 수정)
- 엔티티의 값을 반환한다.
Insert 전에 select 를 호출한 이유는 merge 메서드를 실행했기 때문입니다. persist 메서드 대신 merge 메서드가 실행 된 이유는 조건문에서 사용된 isNew 메서드의 반환값이 false 이기 때문입니다.
isNew()
왜 isNew 메서드가 false 값을 반환했는지 디버깅했습니다.
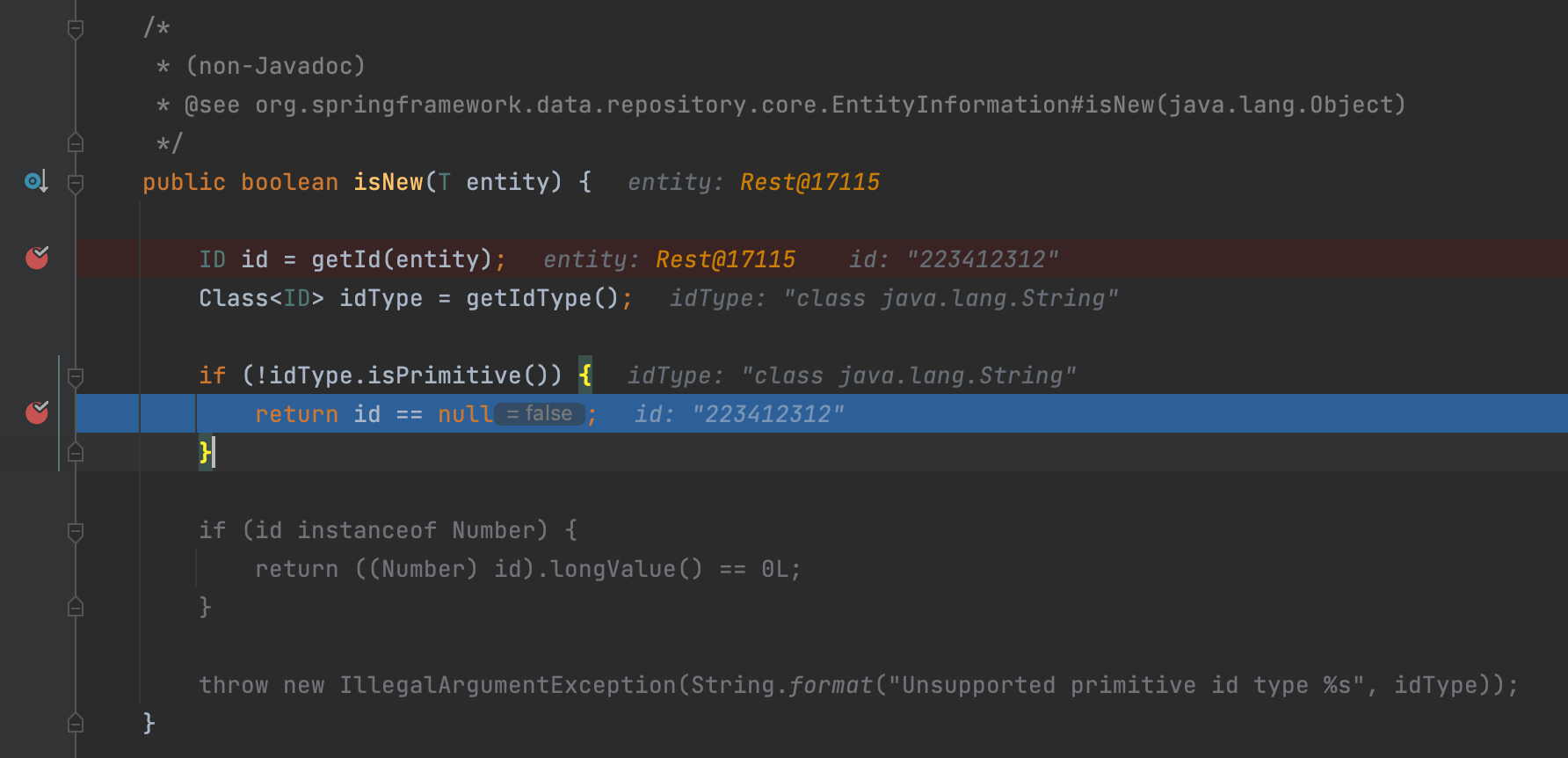
AbstractEntityInformation 추상클래스의 코드입니다. 엔티티로부터 Id를 가져오고 null 이면 true, 아니면 false 값을 반환하는 로직입니다. 따라서 엔티티를 저장할 때 Id 값이 있으면 persist 대신 merge 메서드를 호출한다는 것을 알게되었습니다. 기본 키 직접 할당 전략을 사용하면, 엔티티를 저장할 때 Id 값이 필수로 들어가야 하므로 매번 merge 메서드를 호출하는 성능문제가 존재합니다.
🔑 성능 개선 방법
isNew 메서드 오버라이딩
@EntityListeners(AuditingEntityListener.class)
@Getter
@MappedSuperclass
public abstract class TimeBaseEntity {
// DB 수정자 추가할지 고려
@CreatedDate
@Column(updatable = false)
private LocalDateTime createdAt;
@LastModifiedDate
private LocalDateTime updatedAt;
}저는 Auditing 기능을 사용하고 있습니다. DB에 데이터가 추가될 때, 생성시간 필드가 함께 삽입됩니다.
public class Rest extends TimeBaseEntity implements Persistable<String> {
@Id
@Column(name = "rest_id", nullable = false, length = 16)
private String id;
...
@Override
public boolean isNew() {
return super.getCreatedAt() == null;
}
}Persistable 인터페이스를 사용하면 isNew 메서드를 오버라이딩 할 수 있습니다. 생성 시간이 null 이 아니라는 것은 데이터가 존재한다는 것과 같습니다. 이렇게 하면 엔티티의 Id 값이 존재해도 merge 메서드를 호출할 수 있습니다.
적용 후
 Insert 전에 select 쿼리를 호출하지 않습니다!
Insert 전에 select 쿼리를 호출하지 않습니다!
📄 마치며..
엔티티 라이프사이클과 Merge 메서드의 로직 순서를 공부할 수 있어서 좋았습니다. 디버깅 과정에서 spring-data-commons, spring-data-jpa 에 따라 다르게 구현된 코드들을 보며 어떤 상속 구조를 가졌는지 알게 되었습니다. 테스트 코드를 통해서 성능을 향상시킬 수 있어서 좋았습니다.